
CSVを使ったデータインポートは、CRM運用の中でも慎重さが求められる作業です。
一括で情報を更新できる一方で、「誤って既存データを上書きしてしまった」「重複データが増えて整理が大変になった」といったトラブルも起こりがち。
F-RevoCRMには、こうしたリスクを防ぐために「スキップ」「上書き」「重複マージ」という3種類の処理方法が用意されています。
それぞれの仕組みを理解し、目的に応じて正しく選択することで、データの一貫性と正確性を保ちながら、安全にインポートを実行できます。
本記事では、この3つの処理方法の違いと選び方、インポートを安全に行うためのポイントを解説します。

データインポートとは
CRMや会計ソフトなどの業務システムでは、外部ファイルからまとめてデータを取り込む処理を「インポート(Import)」と呼びます。
たとえば、Excelで管理している顧客リストをシステムに登録したり、別のツールで出力したデータを一括で反映したりする場面がこれにあたります。
インポートを活用すれば、手作業で入力する手間を減らし、短時間で大量の情報を扱うことができます。
一方で、既に登録されているデータと重複したり、上書きしてはいけない情報を更新してしまったりするリスクもあります。
そのため、多くのシステムでは「既存データと同じ内容を見つけたとき、どう処理するか」を選択できるようになっています。
CRMとは?顧客関係管理の基本・メリット・支援サービスまで徹底解説

「スキップ」「上書き」「マージ」の違い
データをインポートするとき、既に同じ情報がシステム内に登録されている場合があります。
その際、既存データと新しいデータをどう扱うかを決めるのが、「スキップ」「上書き」「マージ」といった処理方法です。
この選択によって、取り込み結果が大きく変わるため、仕組みを理解しておくことが大切です。
スキップ【既存データをそのまま残す】
「スキップ」は、既存データと一致する情報が見つかった場合に、新しいデータを登録せず処理を飛ばす方法です。
たとえば、すでに登録済みの顧客情報と同じメールアドレスがCSVに含まれていた場合、その行は無視され、システム上のデータは変更されません。
この方法は、既存データを変更したくないときや、古いデータを誤って取り込みたくないときに使います。
上書き【新しいデータで置き換える】
「上書き」は、既存データを新しい内容で更新する方法です。
インポートしたCSVファイルの情報がシステム上のデータに反映され、古い情報は新しい内容に置き換わります。
ただし、CSVの項目が空欄になっている場合、その項目が空白として上書きされるケースもあります。
「誤ってデータを消してしまった」というトラブルを避けるためにも、実行前にファイル内容を確認しておきましょう。
マージ【既存データと新しいデータを統合する】
「マージ(merge)」は、既存データとインポートデータを突き合わせて統合する方法です。
どちらか一方にしかない情報を補完し、両方の内容を合わせて1つのレコードにまとめます。
たとえば、既存データに「住所」が登録されており、インポートデータに「電話番号」だけが含まれている場合、マージを行うことで、住所と電話番号の両方を持つ完全なデータとして統合されます。
一方で、マッチングフィールド(照合条件)を誤って設定すると、同一のデータを正しく統合できず重複が残ることがあります。
顧客IDではなく名前で照合してしまうと、表記揺れ(山田太郎/ヤマダタロウ)がある場合に別データとして扱われてしまうため注意が必要です。
3つの処理方法の違いを整理
| 動作内容 | 主なメリット | 注意点 | |
| スキップ | 一致データは無視して登録を見送る | 既存データを安全に保持できる | 新しい情報が反映されない |
| 上書き | 既存データを新しい内容で置き換える | 最新情報を反映できる | 空欄があると上書き消去される可能性 |
| マージ | 既存データと新しいデータを統合 | 情報を補完して精度を高められる | マッチング条件を誤ると重複してしまう |
このように、3つの処理方法はそれぞれ利点と注意点が異なります。
どの方法を選ぶかは、目的やデータの性質によって判断することが重要です。
次の章では、これらの仕組みをF-RevoCRMのインポート機能を例に、実際の操作でどのように使い分けられるのかを紹介します。
F-RevoCRMのインポート機能ではどう扱うか
F-RevoCRMでは、インポート時に重複データを検知して自動で処理方法を選択できるようになっています。
具体的には、「スキップ」「上書き」「重複マージ」の3つから動作を指定することで、目的に合わせたデータ取り込みが可能です。
バックアップを取得してから作業する
インポート前には、必ずデータベース全体のバックアップを取得しておきましょう。
想定外の上書きやマッピング設定の誤りがあっても、バックアップがあれば元に戻すことができます。
特に、大量のデータを一度に取り込む場合や、初めてインポート設定を変更する場合は、
バックアップを取ったうえで作業することが安全です。
少量データでテストインポートを実施する
本番のデータを取り込む前に、少量データで試験的に実行して動作を確認しましょう。
小規模のテストであれば、マッチング設定や重複処理の結果を確認しやすく、
不具合を早期に発見できます。
テスト結果に問題がなければ、その設定を本番環境に適用することで、リスクを最小限に抑えながら確実にデータを取り込めます。
よくあるエラーを事前に確認する
インポート時に発生しやすいエラーには、次のようなものがあります。
- CSVファイルの文字コードや区切り文字が異なる
- マッチングフィールド(例:顧客ID、メールアドレス)が重複または未設定
- 必須項目が空欄になっている
これらのエラーは、事前の確認やテストインポートで多くを防ぐことが可能です。
特にマッチングフィールドの設定は、処理結果に直結するため慎重に確認しましょう。
こうした基本を守ることで、データの整合性を保ちながら、
安心してインポートを実施することができます。
F-RevoCRM(エフレボCRM)とは

F-RevoCRMでのインポート設定を安全に行うには
ここまで紹介した内容を踏まえ、最後にF-RevoCRMでインポートを行う際の
設定手順と注意点を確認しましょう。
正しい手順を理解しておくことで、データの一貫性を保ちながら効率的に進められます。
処理方法の選択手順
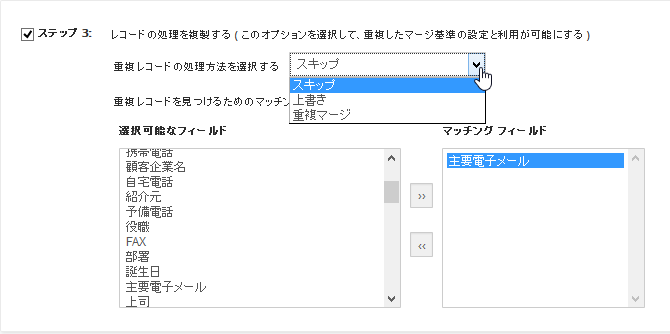
- インポート画面を開く
対象モジュール(例:顧客、案件、見積など)から「インポート」を選択します。 - CSVファイルをアップロード
ファイルの内容を確認し、文字コードや区切り文字を選択します。 - マッチングフィールドを指定
既存データと照合するキー項目(例:顧客IDやメールアドレス)を選びます。
関連記事:F-RevoCRM基本操作シリーズ【データインポート】
実行時の注意点
上書きを選んだ場合は、空欄項目の扱いに注意しましょう。
マージを利用する場合は、どのフィールドを優先するかをあらかじめ理解しておくことが重要です。
複数モジュールを扱う際は、データの依存関係(例:企業情報と担当者情報)を考慮して順にインポートします。
自社データに合わせた運用を検討する
インポート設定は、企業ごとに扱うデータ構造や更新頻度によって最適な方法が異なります。
たとえば、定期的に外部リストを更新する場合は「上書き」中心、
部署間でデータを統合する場合は「重複マージ」中心など、運用ルールを決めておくと安定します。
自社の状況に合った設定を確認したい場合は、F-RevoCRMのデモ環境で操作を試すことも可能です。
実際の画面でインポート手順を体験することで、運用のイメージをより具体的につかめます。
まとめ
インポート作業では、「スキップ」「上書き」「マージ(重複マージ)」の違いを理解し、
目的に応じて正しく選択することが重要です。
それぞれの動作を把握しておけば、データを安全に更新・統合し、CRM全体の正確性を維持できます。
F-RevoCRMでは、これらの処理を柔軟に設定できるため、
自社の運用方針に合わせたデータ管理が可能です。
実際の画面や操作感を確認したい場合は、トライアル環境で試してみるのがおすすめです。
よくある質問
- Qインポートとは何を指しますか?
- A
インポートとは、外部ファイル(例:CSV、Excel)からシステムへデータを一括で取り込む処理を指します。
手作業より効率的に多くの情報を登録・更新できる方法です。
- Q「上書き」と「マージ」の違いは何ですか?
- A
「上書き」は既存データを新しい情報で置き換える処理で、
「マージ」は既存データと新しいデータを突き合わせ、欠けている情報を補完して統合する処理です。
- Qどの方法を選べばよいですか?
- A
既存データを保持したい場合は「スキップ」、新しい情報で更新したい場合は「上書き」、
両方の情報を活かしたい場合は「マージ」を選ぶのが一般的です。
- QF-RevoCRMではどのように設定しますか?
- A
F-RevoCRMのインポート画面でCSVを選択後、
マッチングフィールドを指定し、「スキップ」「上書き」「重複マージ」から処理方法を設定できます。